
NLP Paper Club Week2 (Oct 02 - Oct 09)
Published:
In this blog post I tried to introduce top papers in ML (particularly in NLP) and give a brief overview on them.
Paper #1: LARGE LANGUAGE MODELS AS ANALOGICAL REASONERS
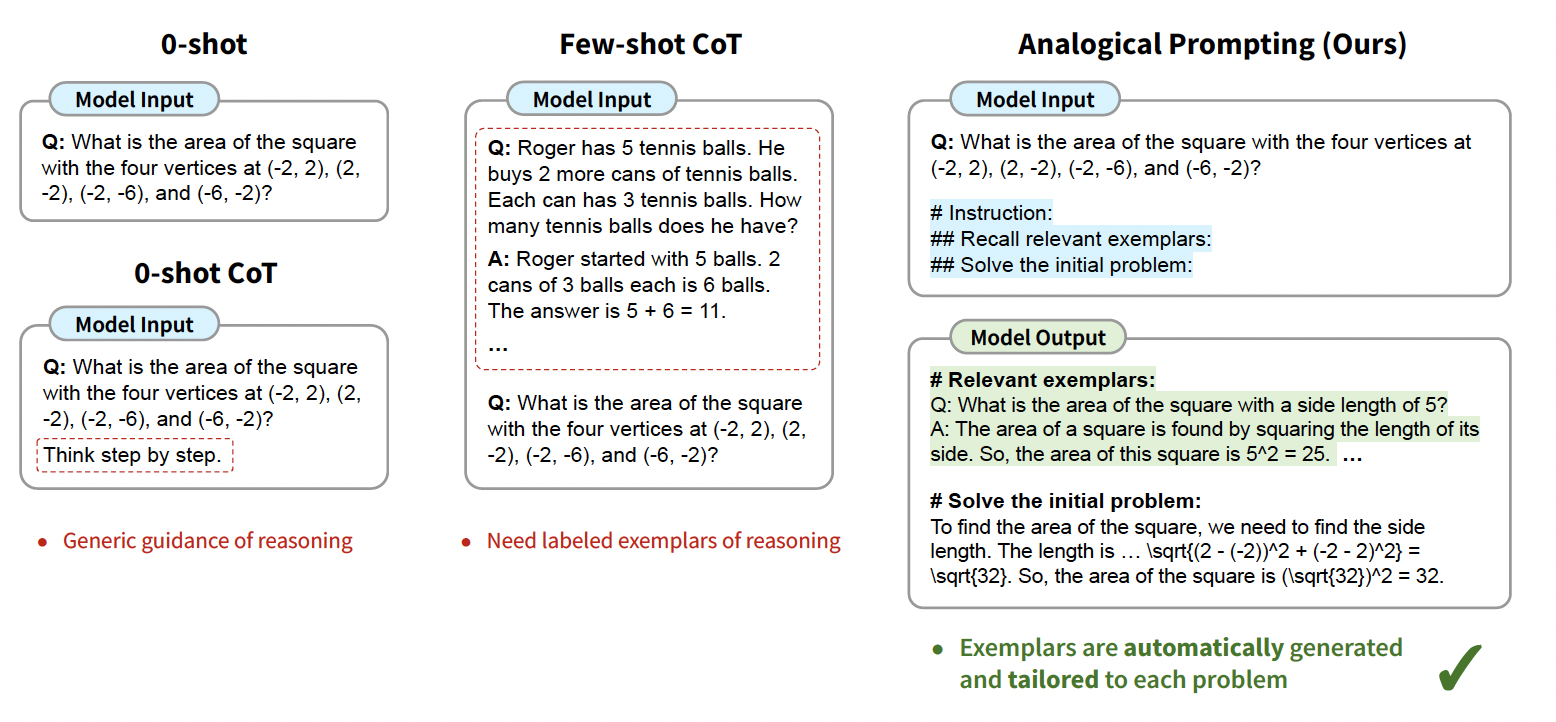
Motivation
Chain-of-thought (CoT) is a prompting strategy that guides LLMs to produce intermediate reasoning steps towards a final answer, enhancing problem-solving performance. Although chain-of-thought prompting (CoT) indicates impressive results on various NLP reasoning tasks, it requires providing relevant guidance or examplars and also manual labeling of examples. Considering these challenges this paper introduces a novel approach to automatically guide the reasoning process of large language models. The inspiration comes from analogical reasoning in psychology where humans draw from relevant experiences. Since modern LLMs have already acquired knowledge of different problems during pre-training, we can employ this knowledge to generate relevant examplars for each task.
Contributions
- This method prompts LLMs to self-generate relevant examplars and obviates the need for manually labeling reasoning examplars for each task.
- The self-generated exemplars are tailored to individual problems, such as ‘geometry’ or ‘probability’, rather than generic ‘math problems’.
- The approach is evaluated on different reasonign tasks and results illustrate this approach outperforms 0-shot CoT and few-shot CoT across a range of tasks.
Methodology
The analogical prompting is a new approach for prompting LLMs to make them self-generate relevant examplars or knowledge in context, before proceeding into solve problem. The paper presents two techniques to achieve it: (1) self-generated examplars, and (2) self-generated knwoledge + examplars.
self-generated examplars
Since LLMs possess a broad range of problem-solving knowledge acquired during pre-training, we can prompting them to recall and generate relevant problems and solutions based on the provided context. This can enhance in-context learning capabilities of LLMs to solve problems. Specifically, given a target problem to solve $X$, the prompt augments the $X$ with instructions as follow (See Figure 2):
- # Problem: [X]
- # Relevant problems: recall three relevant and distinct problems. for each problem describe it and explain the solution.
- # Solve the initial problem:
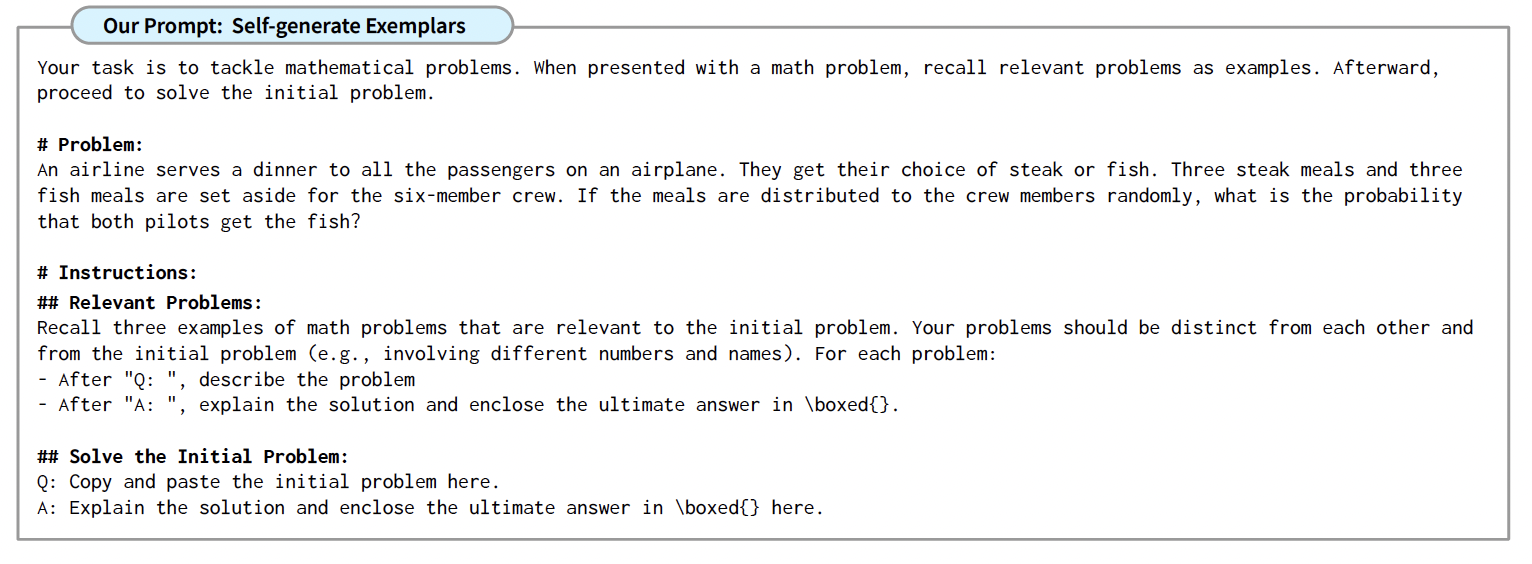
This approach offers detailed exemplars of reasoning without manual labeling, addressing the challenges in 0-shot and few-shot CoT. It also generates task-specific examplars rather than fixed examplars, offering more tailored and relevant guidance to LLMs.
Self-generated Knowledge + Examplars

While generating exemplars is useful, in complex tasks like code generation, LLMs may overly rely on the low-level exemplars and fail to generalize when solving the target problems. To address this challenge, the authors also allow LLMs to self-generate high-level takeaways that complements the exemplars, which is referred to as “knowledge.” This can be done by enhancing the prompt with an additional instruction like the following (See Figure 3):
# Tutorial: identify core concepts in the problem and provide a tutorial.
