
From Local to Global Sensemaking: First Impressions of Microsoft GraphRAG (MS GraphRAG)
Published:

TL;DR GraphRAG replaces vector search with a lightweight knowledge-graph index and a map-reduce summarization step. The result: LLMs can tackle global questions such as “What themes span this entire corpus?” while remaining fast and token-efficient. In head-to-head tests against GPT-4-powered vector RAG, GraphRAG won 72-83 % of comparisons on answer comprehensiveness and 62-82 % on diversity, while using up to 97 % fewer context tokens for some query modes. You can have a look at the implementation of the MS GraphRAG using Neo4j here: MS GraphRAG Implementation

What is Naive (Vector) RAG?
Retrieval Augmented Generation (RAG) refers to a system where a user query is used to retireve most relevant information from external data sources. These relevant information will be provided to an LLM to use and generate the answer based on the user query. Essentially, Naive RAG follows a two-stage approach: Retrieval and Generation.
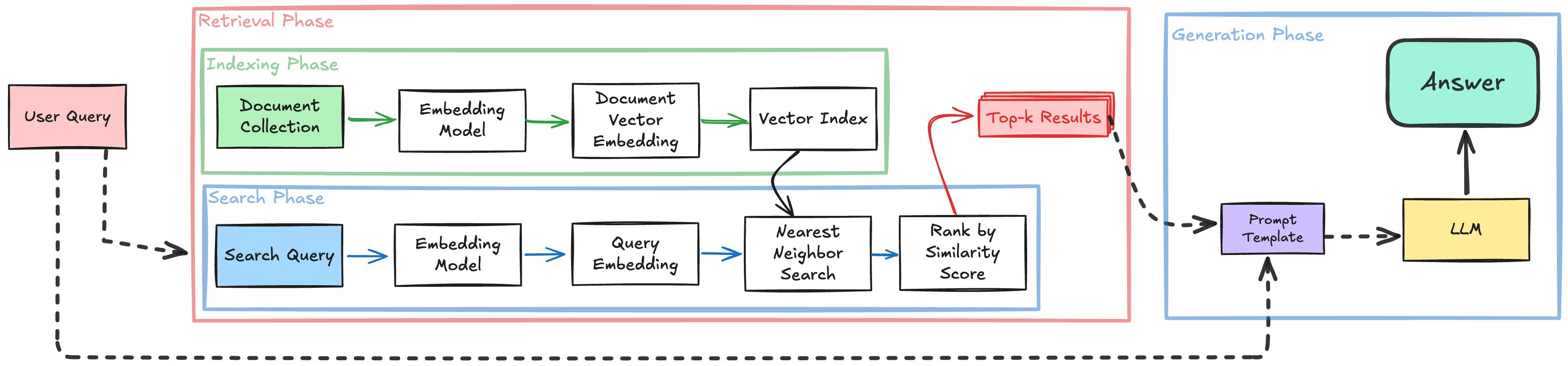
Retrieval Stage consists of two phases:
- Indexing Phase: Documents are split into chunks, converted into vector embeddings using an embedding model, and stored in a vector index. This creates a searchable knowledge base where semantically similar content clusters together in the vector space.
- Search Phase: When a user asks a question, the query is embedded using the same model, and the system performs approximate nearest neighbor search to find the most semantically similar document chunks. These are then ranked by similarity score to produce the top-k results.
Generation Stage: The retrieved top-k results are combined with the user query in a prompt template and fed to the language model to generate the final answer.
This approach works well for local questions where the answer can be found in a few relevant chunks. However, it struggles with global reasoning tasks that require understanding connections and themes across the entire corpus.
Why Does Classic Naive RAG Break Down?
Naive RAG excels when answers exist in a handful of chunks that fit the model’s context window. Global “sensemaking” questions, however, require reasoning across the entire corpus rather than just the top-k nearest neighbours. Sensemaking tasks require reasoning over connections which can be among entities (persons, places) and relations between them. A query like “What overarching themes emerge across the entire dataset?” makes this clear.
To address this limitation, Microsoft proposed and implemented GraphRAG which has become one of the most popular approaches. In this article, we will dive into how GraphRAG works, explore its key innovations, and see why it is proving so effective for global reasoning tasks.
How Does MS GraphRAG work?
GraphRAG is a graph-based extension of Naive RAG designed for global sensemaking over large text corpora. It uses an LLM to first build a knowledge graph of entities and their relationships, then clusters related entities into hierarchical communities. Each community is summarized by the LLM, creating a structured overview of the corpus. At query time, GraphRAG applies a map-reduce strategy: community summaries are used to generate partial answers in parallel, which are then merged into a final, coherent response.
The very first part of this workflow focuses on building a knowledge graph in three different stages:
1. Chunking the Corpus
In this step, the raw documents are split into smaller text chunks. Chunk size is a key design choice. Larger chunks reduce the number of LLM calls but may miss fine-grained information, while smaller chunks improve recall but come at a higher processing cost.
def chunk_text(text: str, chunk_size: int, overlap: int, split_on_whitespaces: bool = True) -> list[str]:
"""
Chunk text into chunks of a given size, with an overlap.
"""
chunks = []
index = 0
while index < len(text):
if split_on_whitespaces:
prev_whitespace = 0
left_index = index - overlap
while left_index >= 0:
if text[left_index] == " ":
prev_whitespace = left_index
break
left_index -= 1
next_whitespace = text.find(" ", index + chunk_size)
if next_whitespace == -1:
next_whitespace = len(text)
chunk = text[prev_whitespace:next_whitespace].strip()
chunks.append(chunk)
index = next_whitespace + 1
else:
start = max(0, index - overlap + 1)
end = min(index + chunk_size + overlap, len(text))
chunk = text[start:end].strip()
chunks.append(chunk)
index = end
return chunks
2. Extracting Entities, Relationships, and Claims
The LLM processes each chunk to extract important entities, their relationships, and relevant claims. For instance, from a sentence about a tech acquisition, the model might extract entities like NeoChip and Quantum Systems, the relationship acquired, and the claim that the acquisition happened in 2016.
def extract_entities_and_relationships(text: str) -> List[str]:
messages = [
{"role": "user", "content": create_extraction_prompt(ENTITY_TYPES, text)}
]
response = chat(messages, model="gpt-4o-mini")
return parse_extraction_output(response)
3. Constructing the Knowledge Graph
The extracted entities and relationships are aggregated across the entire corpus to build a knowledge graph. Entities become nodes, relationships become edges, and repeated mentions strengthen edge weights. Descriptions are summarized and duplicates are reconciled, resulting in a structured and interconnected representation of the dataset (documents).
def store_to_neo4j(driver, chunked_books: List[List[str]]):
number_of_books = 1
for book_i, book in enumerate(
tqdm(chunked_books[:number_of_books], desc="Processing books")
):
for chunk_i, chunk in enumerate(
tqdm(book, desc="Processing chunks")
):
entities, relationships = extract_entities_and_relationships(chunk)
driver.execute_query(import_nodes_query,
data=entities,
book_id=book_i,
chunk_id=chunk_i,
text=chunk)
driver.execute_query(
import_relationships_query,
data=relationships,
)
4. Community Detection: Structuring the Graph
Once the knowledge graph is constructed, GraphRAG applies a hierarchical community detection algorithm, specifically Leiden clustering, to group related entities into tightly connected subgraphs. This step reveals the internal structure of the corpus by identifying clusters of entities that are semantically or contextually related.
The process is recursive: it first finds broad, high-level clusters (root communities), then drills down to identify finer-grained sub-communities within them. This hierarchical grouping is key for enabling divide-and-conquer summarization, where each community is summarized independently before being merged into global insights.
In the visualization below, you can see this structure in action:
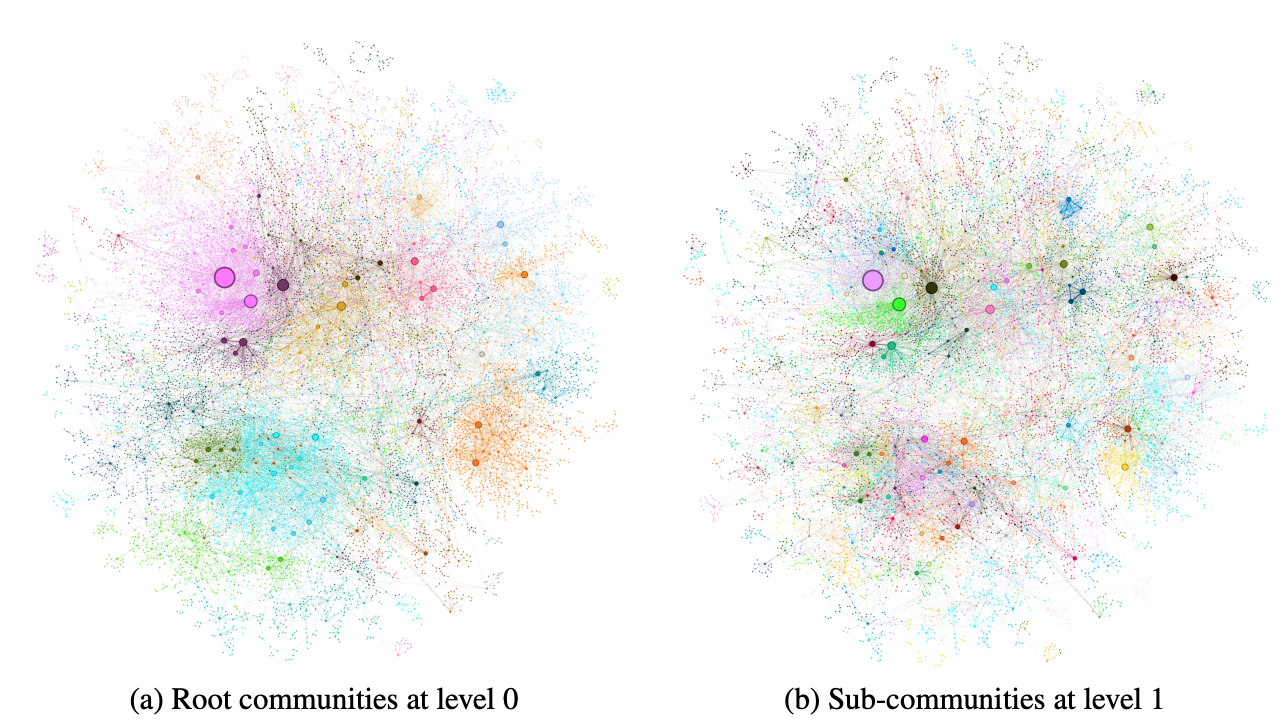
Left (a): Root-level communities (Level 0) show the most general groupings across the corpus.
Right (b): Sub-communities (Level 1) reveal a more detailed breakdown within each root cluster.
def calculate_communities(neo4j_driver):
# Drop graph if exist
try:
neo4j_driver.execute_query("""
CALL gds.graph.drop('entity')
""")
except:
pass
neo4j_driver.execute_query("""
MATCH (source:__Entity__)-[r:RELATIONSHIP]->(target:__Entity__)
WITH gds.graph.project('entity', source, target, {}, {undirectedRelationshipTypes: ['*']}) AS g
RETURN
g.graphName AS graph, g.nodeCount AS nodes, g.relationshipCount AS rels
""")
records, _, _ = neo4j_driver.execute_query("""
CALL gds.louvain.write("entity", {writeProperty:"louvain"})
""")
return [el.data() for el in records][0]
5. Community Summarization: Turning Structure into Insight
With the graph now organized into a hierarchy of communities, GraphRAG moves on to generating summaries for each of these clusters. These act like mini-reports describing the entities, relationships, and key claims in each community. Importantly, these summaries serve the final query and offer an independent, human-readable overview of the corpus structure.
Summarization happens in two main layers:
Leaf-level communities (the most granular clusters) are summarized by prioritizing their most important elements: prominent nodes and edges. The LLM includes as many of these as possible within its context window, starting with the most connected nodes and relationships (i.e., the “hubs” of that subgraph).
Higher-level communities (larger clusters comprising sub-communities) are summarized bottom-up. The LLM processes them directly if all the detailed element summaries still fit into the context window. Otherwise, the system switches to using already-generated summaries of sub-communities, which are shorter and more abstract, to stay within the token limit.
def community_summary(driver: neo4j.Driver):
community_info, _, _ = driver.execute_query(community_info_query)
community_summaries = []
for community in tqdm(community_info, desc="Summarizing communities"):
messages = [
{"role": "user", "content": get_summarize_community_prompt(community["nodes"], community["rels"])}
]
response = chat(messages, model="gpt-4o")
community_summaries.append({
"community": json.loads(extract_json(response)),
"communityID": community["communityId"],
"nodes": [el["id"] for el in community["nodes"]],
})
driver.execute_query(import_community_query, data=community_summaries)
6. Answering Queries: From Partial Insights to a Global Response
Once the community summaries are in place, GraphRAG can answer user queries through a map-reduce-style process that balances efficiency and depth. Because summaries exist at multiple levels of the hierarchy, the system can choose the right level of granularity depending on the type of question—broad, thematic queries may benefit from high-level summaries. In contrast, detailed queries might use more specific ones.
Here is how the process works:
Prepare the input: Community summaries are shuffled and grouped into token-sized chunks. This process prevents key information from clumping into a single block that the LLM might truncate or ignore.
Map stage: The LLM generates a partial answer to the user’s query for each chunk, along with a helpfulness score (0–100) indicating how relevant that chunk’s information is. Chunks with a score of 0 are discarded.
Reduce stage: The most helpful partial answers are then sorted by score and merged into a single context. The LLM uses this refined input to generate the final, global answer to the query.
def global_retriever(driver: neo4j.Driver, query: str, rating_threshold: float = 5) -> str:
community_data, _, _ = driver.execute_query("""
MATCH (c:__Community__)
WHERE c.rating >= $rating
REturn c.summary AS summary
""",
rating=rating_threshold)
print(f"Got {len(community_data)} communitiy summaries")
intermediate_results = []
for community in tqdm(community_data, desc="Retrieving community summaries"):
messages = [
{"role": "system", "content": get_map_system_prompt(community["summary"])},
{"role": "user", "content": query}
]
intermediate_response = chat(messages, model="gpt-4o")
intermediate_results.append(intermediate_response)
final_messages = [
{"role": "system", "content": get_reduce_system_prompt(intermediate_results)},
{"role": "user", "content": query}
]
final_response = chat(final_messages, model="gpt-4o")
return final_response
Local Search: Entity-Focused Query Resolution
While global search excels at answering broad, thematic questions by leveraging community summaries, local search takes a more targeted approach by focusing on specific entities and their immediate context. This method is particularly effective for queries about particular people, places, or concepts that have been explicitly identified in the text.
Here’s how local search operates:
Entity matching: The system converts the user query into an embedding and performs vector similarity search against entity embeddings to find the most relevant entities in the knowledge graph.
Context gathering: For each matched entity, the system collects:
- Text chunks that mention these entities, ranked by how many relevant entities they contain
- Community summaries that the entities belong to, providing broader context
- Relationship descriptions between the matched entities, capturing their interactions
- Entity descriptions themselves, offering direct information about each entity
Response generation: The gathered context is assembled into a structured format and used to generate a focused answer that draws from the most relevant entity-specific information.
This dual approach—global search for thematic questions and local search for entity-specific queries—allows GraphRAG to handle a wide range of question types with appropriate depth and focus.
def generate_embedding_for_entities(driver: neo4j.Driver):
entities, _, _ = driver.execute_query("""
MATCH (e:__Entity__)
WHERE e.summary IS NOT NULL AND e.summary <> ''
RETURN e.summary AS summary, e.name AS name
"""
)
data = [{"name": el["name"], "embedding": embed(el["summary"], model="all-MiniLM-L12-v2")[0]} for el in entities]
driver.execute_query("""
UNWIND $data AS row
MATCH (e:__Entity__ {name: row.name})
CALL db.create.setNodeVectorProperty(e, 'embedding', row.embedding)
""",
data=data,
)
driver.execute_query("""
CREATE VECTOR INDEX entities IF NOT EXISTS
FOR (n:__Entity__)
ON (n.embedding)
""",
data=data,
)
def local_search(driver: neo4j.Driver, query: str, k: int = 5, top_chunks: int = 3, top_communities: int = 3, top_inside_rels: int = 3) -> str:
local_search_query = """
CALL db.index.vector.queryNodes('entities', $k, $embedding)
YIELD node, score
WITH collect(node) as nodes
WITH collect {
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT $topChunks
} AS text_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT $topCommunities
} AS report_mapping,
collect {
UNWIND nodes as n
MATCH (n)-[r:SUMMARIZED_RELATIONSHIP]-(m)
WHERE m IN nodes
RETURN r.summary AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topInsideRels
} as insideRels,
collect {
UNWIND nodes as n
RETURN n.summary AS descriptionText
} as entities
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: insideRels,
Entities: entities} AS text
"""
context, _, _ = driver.execute_query(local_search_query,
k=k,
topChunks=top_chunks,
topCommunities=top_communities,
topInsideRels=top_inside_rels,
embedding=embed(query, model="all-MiniLM-L12-v2")[0]
)
context_str = str(context[0]["text"])
messages = [
{"role": "system", "content": get_local_system_prompt(context_str)},
{"role": "user", "content": query}
]
response = chat(messages, model="gpt-4o")
return context_str, response
Conclusion
GraphRAG represents a significant advancement over traditional vector-based RAG by combining knowledge graph construction with hierarchical summarization to support true global sensemaking. Unlike vector-only retrieval, GraphRAG can navigate the graph structure to uncover directly relevant content and indirectly related information by following meaningful relationships between entities. This process allows it to generate richer, more context-aware responses, especially in complex or exploratory tasks. By filtering and ranking retrieved elements based on user context and task, GraphRAG enhances both the relevance and precision of answers. Its structured design also improves explainability, making tracing the origins and logic behind each response easier. Altogether, GraphRAG delivers more comprehensive, accurate, and efficient answers at a fraction of the token cost, making it a compelling solution for working with large, interconnected datasets.
You can have a look at the implementation of the MS GraphRAG using Neo4j here: MS GraphRAG Implementation